|
I am a Research Engineer at the Center for Cyber Security , New York University, Abu Dhabi since November 2022. Currently, I am working on analyzing and mitigating the effect of concept drift on misinformation detection classifier performance over time. Prior to that, I was an MS by Research student at the Department of Computer Science & Engineering , Indian Institute of Technology, Kharagpur ( IIT Kharagpur ) from January 2019 to September 2022. My master's thesis was on developing a scalable and explainable approach to aspect knowledge information incorporation into the Aspect Based Sentiment Analysis task [ PDF]. |

|
|
My research interests include robustness, generalizability and interpretability of deep neural models, understanding capabilities of LLMs through knowledge probing and understanding mechanisms behind in-context-learning and constrained text generation. I aim to explore LLMs' generalization capabilities on out-of-distribution data, focusing on longer and compositional proof reasoning and understanding the in-context learning mechanism. Despite significant progress in LLMs, challenges persist in multimodal language modelling, knowledge probing, and maintaining trustworthiness, particularly in multimodal data. Additionally, ongoing pursuits include addressing challenges in emotional response and counter-response generation against misinformation, propaganda-based misinformation generation, and adversarial training for early detection scenarios. |
|
|
|
|
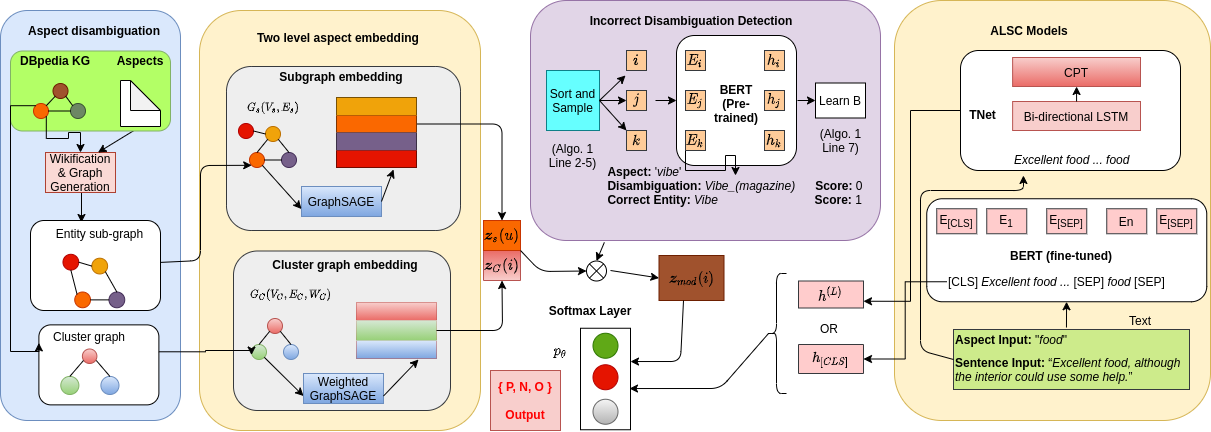
Sk Mainul Islam , Sourangshu Bhattacharya The Web Conference (WWW), 2022 Aspect level sentiment classification (ALSC) is a difficult problem with state-of-the-art models showing less than 80% macro-F1 score on benchmark datasets. Existing models do not incorporate infor- mation on aspect-aspect relations in knowledge graphs (KGs), e.g. DBpedia. Two main challenges stem from inaccurate disambigua- tion of aspects to KG entities, and the inability to learn aspect representations from the large KGs in joint training with ALSC models. We propose AR-BERT, a novel two-level global-local entity embedding scheme that allows efficient joint training of KG-based aspect embeddings and ALSC models. A novel incorrect disam- biguation detection technique addresses the problem of inaccuracy in aspect disambiguation. We also introduce the problem of deter- mining mode significance in multi-modal explanation generation, and propose a two step solution. The proposed methods show a consistent improvement of 2.5 − 4.1 percentage points, over the recent BERT-based baselines on benchmark datasets. |
|
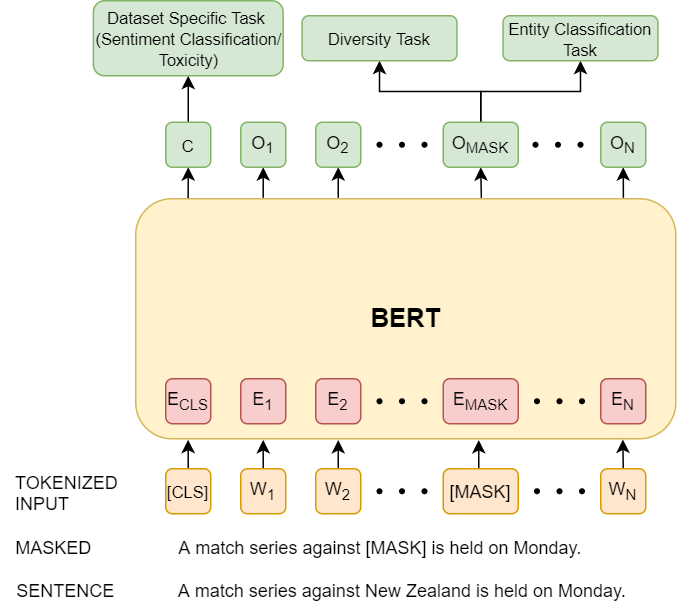
Sk Mainul Islam , Abhinav Nagpal, Balaji Ganesan, Pranay Kumar Lohia CtrlGen Workshop at NeurIPS (NeurIPS-W), 2021 Natural language text generation has seen significant improvements with the advent of pre-trained language models. Using such language models to predict personal data entities, in place of redacted spans in text, could help generate synthetic datasets. In order to address privacy and ethical concerns with such datasets, we need to ensure that the masked entity predictions are also fair and controlled by application specific constraints. We introduce new ways to inject hard constraints and knowledge into the language models that address such concerns and also improve performance on this task. |
|
Updated on |