I am a second-year PhD fellow at the CopeNLU group, University of Copenhagen, supervised by Prof. Isabelle Augenstein and Asst. Prof. Pepa Atanasova. My research sits at the intersection of explainability, fact-checking, and robustness in large language models — with a particular focus on interpretable reasoning for misinformation detection and trustworthy NLP systems.
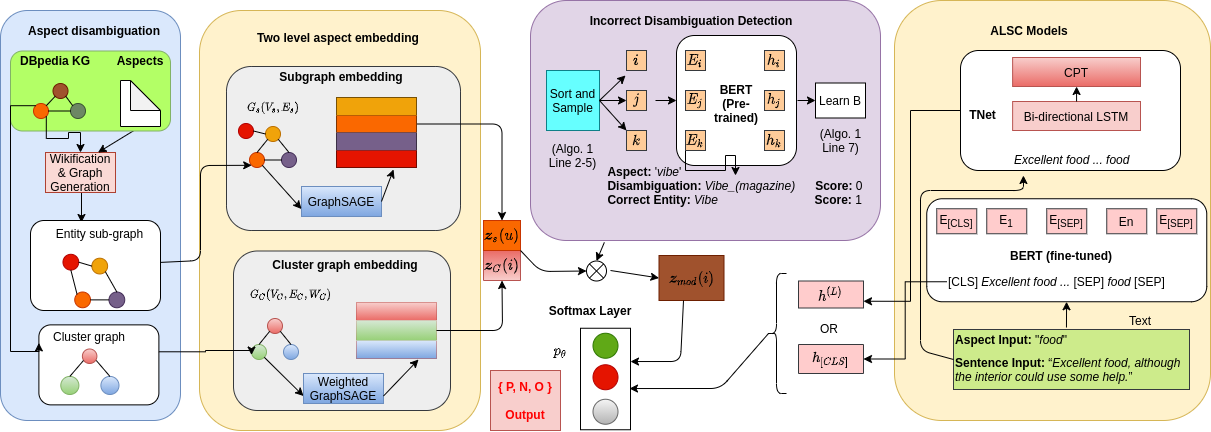
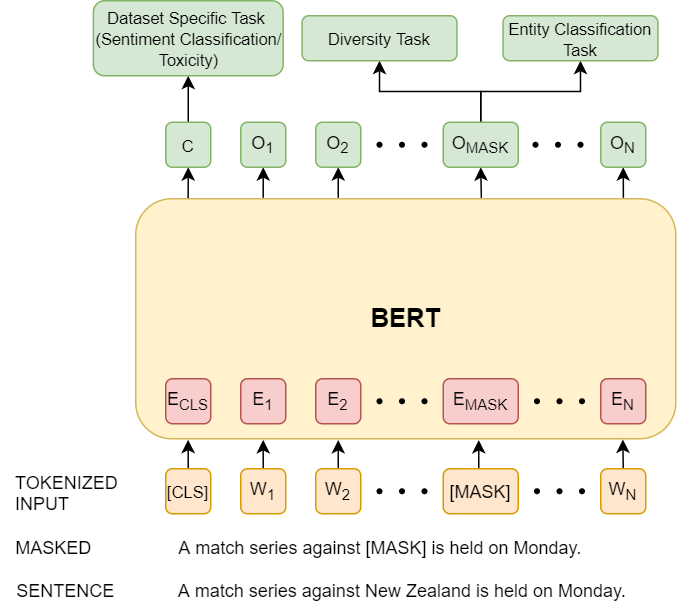
Before Copenhagen, I was a Research Engineer at the Center for Cyber Security, NYU Abu Dhabi (2022–2024). I hold an MS by Research from IIT Kharagpur, where my thesis developed scalable, explainable methods for Aspect-Based Sentiment Analysis.
I am currently looking for PhD Reserach Internship and research scientist internships position for summer 2027.